# AFL 基础学习
# 前言:AFL 适用于 Linux 环境下的 C/C++ 程序进行自动化的 Fuzzing 测试工具。
# 一、Fuzzing 对象
(1)针对已知源码的程序,AFL 提供 afl-gcc/g++/clang 对其进行插桩编译,通过使用种子(testcase 我的理解是语料库)进行变异、遗传算法等策略,再对软件的输入输出流进行测试,从而使程序 crash,接着再从 crash 中查看具体的执行语句、执行位置,接着收集信息用于触发漏洞的 testcase 制作,再使用 gdb 对程序进行调试,发现并触发 testcase 测试漏洞。(根据很多比较新的 fuzz 文章都提倡使用 clang 或 clang 来进行编译插桩,也许是在编译角度上无论是速度还是优化都更优于 gcc/g。)
(2)针对无源码的程序,有两种解决办法:1、利用 QEMU 模拟器对其二进制文件进行插桩。2、使用传统的 - n 参数直接进行测试。对于第二种方法网上可以找到的资料很少,感觉并不适用,因为既然可以使用 QEMU 进行插桩,显然可以提高 fuzz 的成功率,所以在这里就没有过分深究这种方法。
# 二、关于代码插桩
# 1、代码插桩到 fuzzing 的流程:
a. 调用 linux 下汇编器 as 插入桩代码 → b. forksever 进行 fork 与 fuzzer 通信 → c. AFL 使用共享内存进行 fuzzer 与 target 程序之间的信息传递 → d. 不同的 fork 信息进行记录。

# 2、调用 linux 下汇编器 as 插入桩代码:
我们知道源码编译过程是:高级语言代码→汇编代码→二进制代码,根据该文章和资料提供的样例,发现的确在编译过程,生成了一个 as 文件夹,再根据 linux 下的汇编器是 as,可以明确插入桩代码的关键点在于 "汇编代码" 的阶段,并且在 AFL 的目录下也找到了 afl-as.c 文件,对其源代码和资料进行分析可知:在分支处插入的代码为:
fprintf(outf, use_64bit ? trampoline_fmt_64 : trampoline_fmt_32, R(MAP_SIZE)); |
这里的参数 R (MAP_SIZE) 是关键,接下来,按照文章的逻辑分析 trampoline_fmt_32 为例的情况:
trampoline_fmt_32 内容大致可以概括为:(1)将分支处 ecx 寄存器值设置为 fprintf 中的内容。
(2)调用 call 函数执行__afl_maybe_log () 方法。
再解读 fprintf 中的内容:(根据文章的解读进行概括)ecx 中的值就是 R (MAP_SIZE),接着作者分析了宏 MAP_SIZE 的定义,可知其大小为 64K,再给出 R (X) 的定义为:(random () % (x))。因此这样就很容易理解,ecx 寄存器中的值被设置为了 0 到 MAP_SIZE 中的一个随机数。
总结:由以上分析可知,每当编译到一个分支都会插入这段代码,同时修改 ecx 寄存器的值为 afl-as 生成的随机数,这个随机数是用来识别该段分支代块的 key。
# 3、 forksever 进行 fork 与 fuzzer 通信:
引用文章原文:“启动 target 进程后,target 会运行一个 fork server;fuzzer 并不负责 fork 子进程,而是与这个 fork server 通信,并由 fork server 来完成 fork 及继续执行目标的操作。这样设计的最大好处,就是不需要调用 execve() ,从而节省了载入目标文件和库、解析符号地址等重复性工作”
(由于现阶段并不是很清楚是否需要深究这套机制原理,所以在概念上引用了文章原话)
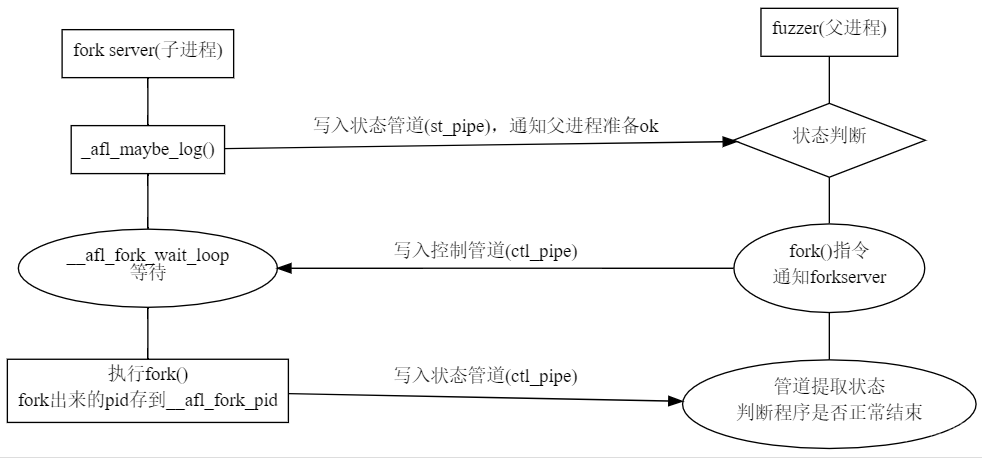
总结:为了高效完成 fuzzing,AFL 使用 forksever 的机制。并在该机制中使用了__afl_maybe_log () 方法,及该方法中的其他方法。其目的主要是如上文所述,其次还有传递给 fuzzer 不同 fork 的执行情况并记录。
# 4、AFL 使用共享内存进行 fuzzer 与 target 程序之间的信息传递:
AFL 使用共享内存的主要目的用于 fuzzer 与 target 程序之间的信息传递,在 fuzzer 启动的时候会分配一块共享内存,该共享内存大小为 MAP_SIZE 为 64K,当使用 forksever 模式进行,该共享内存就是在该模式下进行的。此外,当 fork 的子进程直接会使用这个共享内存。(暂时不做深究,目的在于现阶段了解机制)
# 5、不同的 fork 信息进行记录 & 分析:
完成了上述三个流程,接下来就要搞清通信的内容。看了文章再结合文章中所给的 AFL 源码中的伪代码,可以总结为:“AFL 是根据二元 tuple (跳转的源地址和目标地址) 来记录分支信息,从而获取 target 的执行流程和代码覆盖情况。” 而这里的记录的分支信息是什么呢?AFL 插桩的时候在每个分支会生成一个随机数用来记录,并对分支处的 "原位置" 与 "目标位置" 进行异或,异或的结果标记为该分支段的 key(其保存每个分支执行的次数)。因此,每当执行分支都会改变其 key 值。用于保存 key 值的实际上是一个哈希表,大小为 MAP_SIZE 为 64K。
fuzzer 除了 dumb 模式的无脑更为随机化的测试,都是有着测试路径的,因此每条路径的执行情况,都是通过计算其 hash 值来进行判断的。
# 总结:我现阶段对编译插桩的浅显理解为,其主要目的在于记录并分析代码分支段的执行情况、次数、崩溃情况等等。
⚠️资料参照 https://rk700.github.io/2017/12/28/afl-internals/ 这篇分析
# 三、关于 AFL 的种子变异策略
(由于没有深入研究源码,因此仅对变异的策略进行大致的了解)
# (1)文件变异方法:
1、bitflip:位反转。将每一位 bit(一位、相邻两位…)进行 0 变 1,1 变 0 的操作。
2、arithmetic:从每 8bit 级别(byte、word、dword)进行加减操作。
3、interest:和 arithmetic 操作类似,但不是进行加减,而是对文件内容进行替换;
4、dictionary: 用户提供的字典里有 token,用来替换要进行变异的文件内容,如果用户没提供就使用 bitflip 自动生成的 token。(这点不是很理解)
5、havoc:“大破坏”。指对文件进行真正的随机化处理,进行绝大程度上的 "变异",做到绝对的 "破坏",使其成为一个 "新" 文件。
6、splice:"拼接" 文件,通过一定规则,如:两文件差异不大,就舍弃重选;如果差异很大,就把文件半劈拼接成一个新的文件。
# (2)文件变异策略:
dumb mode 和主 fuzzer 才会进行 deterministic fuzzing 过程(bitflip、arithmetic、interest、dictionary)的操作。而 havoc、splice 是真正的随机化,是每一个 fuzzing 都会进行的变异操作过程。
(这里存在争议,在不同的文章中发现结论并不一致,不排除无脑搬运的情况,根据对源码的分析,认为应该以 https://www.cnblogs.com/wayne-tao/p/12019499.html 这篇文章为准,从逻辑上分析变异的随机性与不随机性更说得通)。
在第一次变异后生成的文件,会在 cycle 队列中循环往复的变异下去,并且不会再进行和第一次一样的 deterministic fuzzing 操作,之后的变异循环只有随机性的变异操作了。
# 四、AFL 相关工具使用及参数解读:
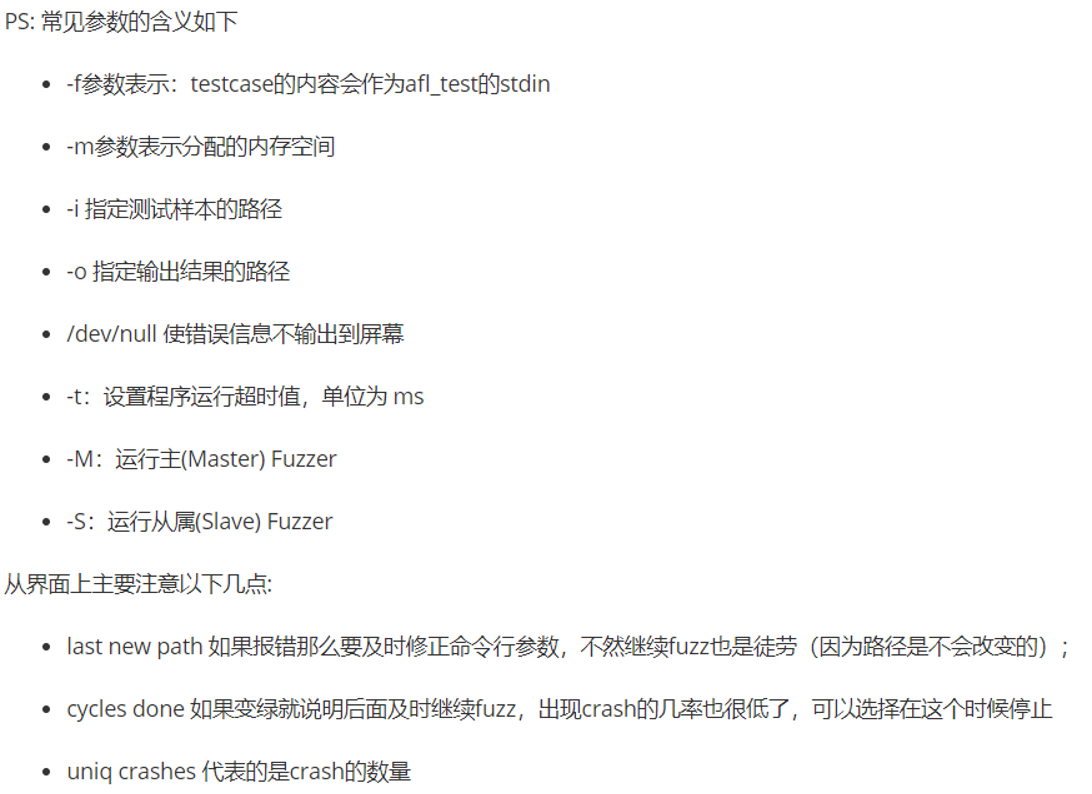
# 1、afl-fuzz 常用参数:
# 2、afl 常用工具:
# (1)afl-cmin:

a. 先创建一些随机输入的 case(随便输入些乱七八糟的字符串)用于构建一个有相对内容的 corpus
b. 查看 afl-cmin 的使用指南:
,-o是输出的最小case的内容(out),其他一些参数和afl-fuzz没有什么区别。")
c. 使用 afl-cmin -i fuzz_in -o fuzz_cmin_out ./test1 命令进行 cmin 修减 corpus

d. 最后整合的结果居然只有这么点。。。其实也可以理解,毕竟我写的 case 只是单纯在这个基础上进行的无效输入。
# 总结:cmin 的处理方式以我的例子来看再结合资料,可以知道 cmin 就是从 case1 开始测试,如果 case2…case the end 都会达到相同的效果,那么在测试的过程中逐一舍去,只保留 case1.
# (2)afl-tmin:

tmin 的目的看上去和 cmin 没什么太大差别,但是不同的是,tmin 仅对单个文件进行 minimization 操作,并输出单个文件,那么就要看一下它是如何进行的。
a. 也是先来看下 tmin 的指南:

b. 使用命令 afl-tmin -i fuzz_in/test_6.testcase -o fuzz_tmin_out ./test1 测试:
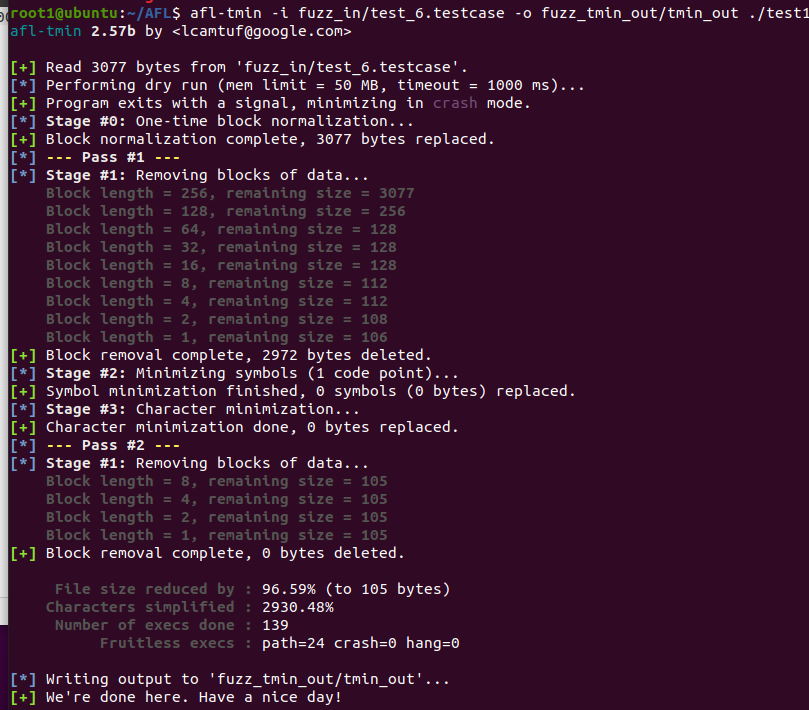
c. 查看 tmin 后输出的 case 文件:

经过查阅资料了解到,如果 case 文件写的太垃圾,tmin 觉得没用,就会全部删掉,但是看到这个资料的师傅遇到了一个 [!] WARNING: Down to zero bytes - check the command line and mem limit! 的问题,我认为理应我也应该出现这个错误提示,但是在这里却没有提示,也是很迷惑。。。但是原理搞懂了就好,目前由于没有研究源码,所以此处也没法深究太多。
https://www.cnblogs.com/wayne-tao/p/11889718.html
注:tmin -i 的单个文件不一定是文本文件,也可以是 binary 文件!
# (3)afl-plot:
根据 afl-plot 的说明可知,在一次模糊测试的过程中他会生成相关的图片和 html 用来统计一些信息。
a. 第一次执行 afl-plot fuzz_out out_image 的时候不成功,提示找不到 gnuplot,后来查了一下 gnuplot 是一个画图工具,因此需要安装一下 gnuplot

执行:sudo apt-get install gnuplot
b. 安装好之后,按照指令,从 fuzz 输出的文件夹,生成图表到一个空 dir 中:
c. 直接进入网页端查看生成的 plot:


# (4)afl-whatsup:
当开多个窗口进行 fuzz 的时候就需要一个全局管理器,用于查看该管理器(容器)中的各个子窗口的执行情况,这个时候可以使用 whatsup 进行管理。
这里对指令进行了了解,但是由于我的配置原因没法进行并行测试,所以这个暂且搁置,目前似乎也不是很重要,只是辅助功能。
# 五、完整 Fuzzing 测试流程
# 1、对有源码程序进行普通 fuzzing 测试:
(1)安装 afl 并使用 afl-gcc 进行源码编译:

(2)执行 afl-fuzz -i dir -o dir ./exec 命令


(3)执行 fuzz 命令之后出现了个奇怪的问题:
的问题困扰了我很久,排除了1、内存大小限制 2、标准输入流stdin(-f)参数 3、使用@@加路径 这几个方法都不能解决这个问题,后来经过不断的尝试发现这个问题,提示命令行参数语法错误的原因在于,源代码中的stdin输入路径是有问题的,这个地方我目前的水平没法给出一个非常明确的解释,但可以肯定的是和源代码有关,如文件头、输入流stdin的定义等等。起初代码中将gets改为read(stdin, buf, 100)并不管用,后来换了一套别人用来测试的写好的代码,居然解决掉这个问题了。看来问题还是出现在源码上。。。")
使用的源码如下:
#include <stdio.h> | |
int main(int argc, char *argv[]) | |
{ | |
char buf[100] = {0}; | |
scanf("%s",&buf); | |
//gets(buf); | |
printf(buf); | |
return 0; | |
}*/ | |
#include <stdio.h> | |
#include <stdlib.h> | |
#include <unistd.h> | |
#include <string.h> | |
#include <signal.h> | |
int vuln(char *str) | |
{ | |
int len = strlen(str); | |
if(str[0] == 'A' && len == 66) | |
{ | |
raise(SIGSEGV); | |
// 如果输入的字符串的首字符为 A 并且长度为 66,则异常退出 | |
} | |
else if(str[0] == 'F' && len == 6) | |
{ | |
raise(SIGSEGV); | |
// 如果输入的字符串的首字符为 F 并且长度为 6,则异常退出 | |
} | |
else | |
{ | |
printf("it is good!\n"); | |
} | |
return 0; | |
} | |
int main(int argc, char *argv[]) | |
{ | |
char buf[100]={0}; | |
gets(buf);// 存在栈溢出漏洞 | |
printf(buf);// 存在格式化字符串漏洞 | |
vuln(buf); | |
return 0; | |
} |
(4)解决掉这个问题之后,发现 crash,但是此时需要确定什么时候应该结束 fuzzing
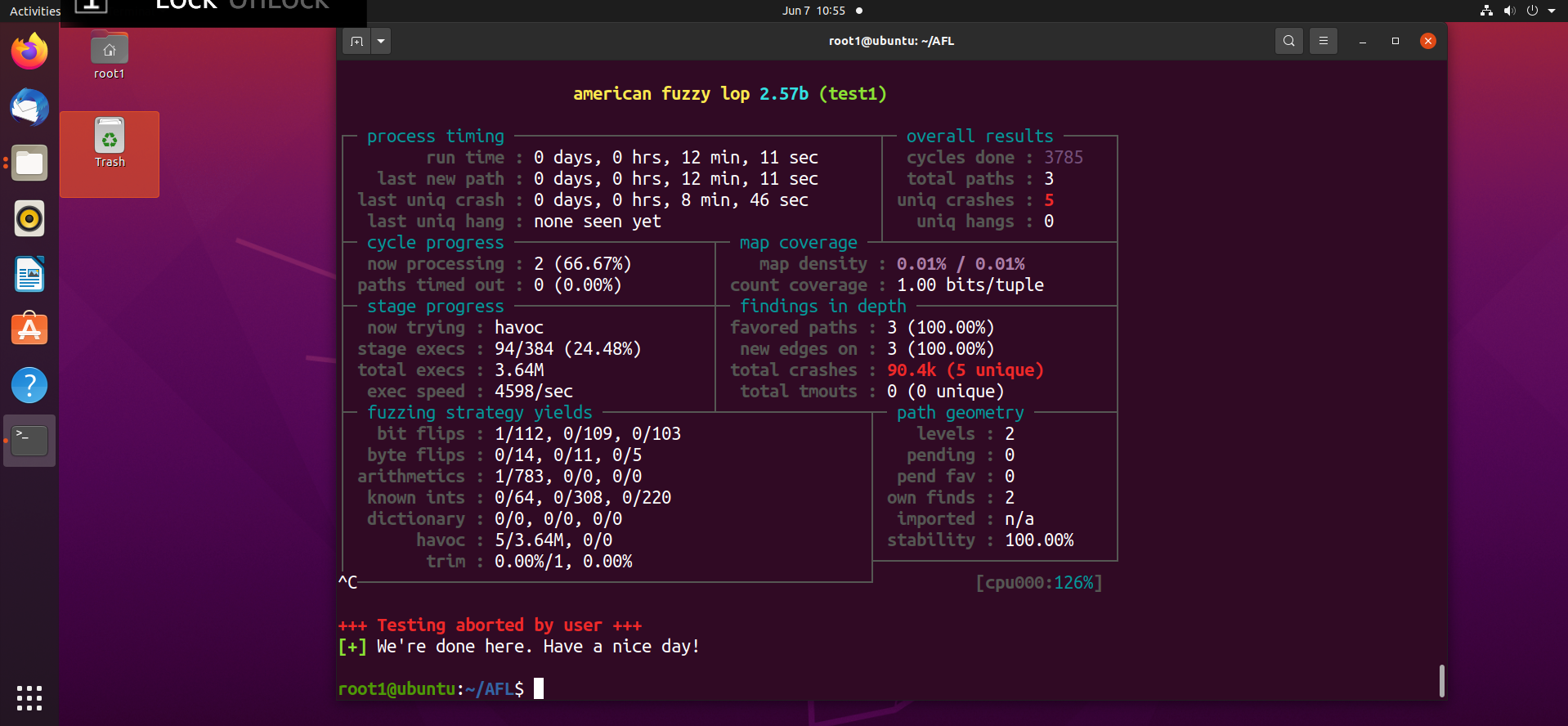
根据资料和对官方源码的部分分析,可知从 process timing 块中的 last uniq crash(最近一次 crash 的时间)分析,如果该时间很长时间都没有更新,说明无论文件如何变异,对其测试的路径都没有更新了,结合上面提到的 "插桩编译、信息传递" 的知识不难理解此时已经没有什么有价值的 crash 值得等待了,这个时候就该 crtl+c 结束 fuzzing 了。
(当然简单的 fuzzing 可以通过 cycles done 的颜色变化来决定什么时候结束 fuzzing)
(5)分析 crash 并验证(小迷惑):
这里用到了一个叫地址消毒的工具,也是 google 开发的,叫做 ASAN(Address Sanitizer)是一种地址错误检查器。
先使用 xxd 对得到的 binary 文件进行 dump 查看一下内容:




光得到 crash 文件仅仅是开始,我们还要看下触发异常的位置、代码行号、可能的问题类型:
这里就要使用之前提到的 ASAN 做定位:(这里仅对两个 crash 进行验证)
a. 首先使用 - fsanitize=address 参数重新编译源代码:

b. 运行编译出来的 a.out 文件,输入 crash 样本中的内容,得到 aborting 分析:
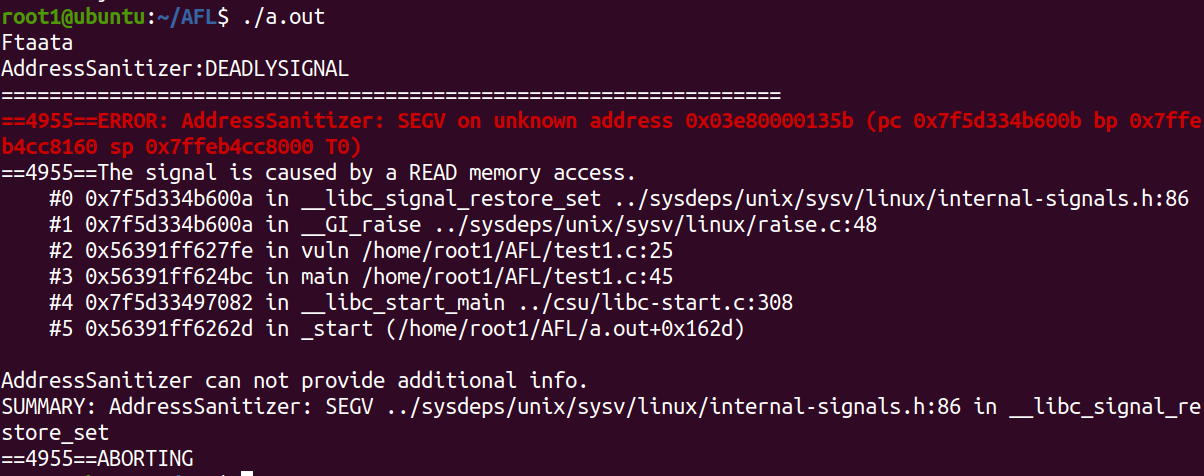
c. 另一个 crash 分析报告如下:
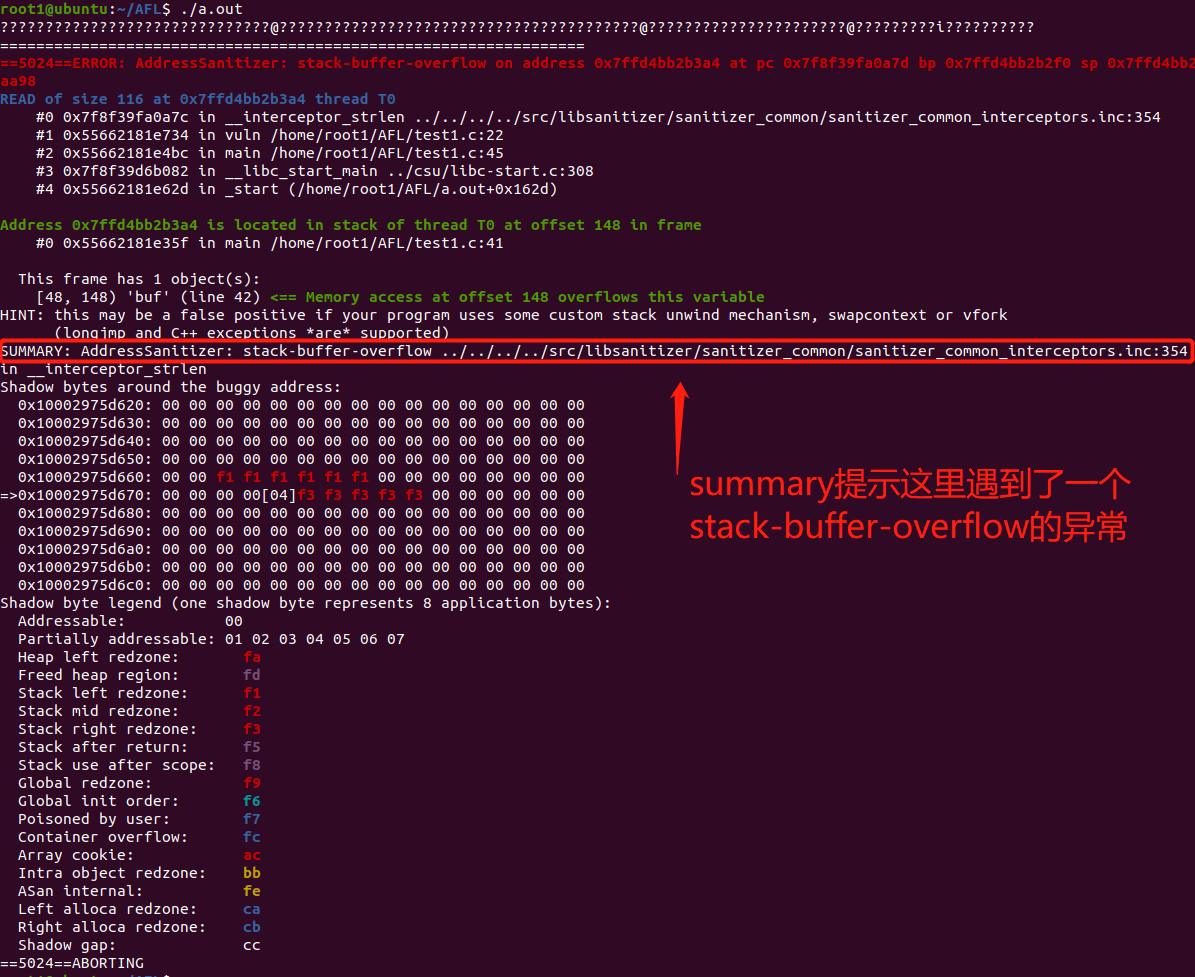
# 2、对有源码程序进行 dumb mode (-d) 测试:
貌似加了 - d 参数并没有什么特别的,可能只是因为单纯改变了变异策略,并不影响测试结果(对于开源小代码)
# 3、对有源码程序进行并行测试 fuzzer (-M -S):
我个人认为对于多线程的系统来讲,单纯对大项目进行单一的主线程 fuzzing 是浪费资源,为了充分提高资源利用率,AFL 提供了并行模式,-M (Master)、-S (Slave),M 为主进程,S 为子进程(把 M 比作 father,S 就是 son)很容易理解,使用方法就是 - M/S 参数后加 name

# 4、对无源码的程序进行 QEMU mode 测试:

错误未解决:

按部就班的进行直到出现这个问题。。。非常无语,查阅了相关的资料,可以得出一个结论就是 qemu 可能并不支持 python3,他兼容的是 python2.7 版本,我不太想进行环境更改,因为这个虚拟机还有很多任务要用到 python3。我想到的解决方法:1、等技术成熟了尝试修改 afl 使其兼容 python3 的版本(估计够呛) 2、有时间重新配置一台虚拟机,目前碍于硬盘空间问题只能暂时搁置。
# 六、关于 AFL 生态介绍
https://bbs.pediy.com/thread-251051.htm 这篇文章详细介绍了 AFL 的生态:不同的插件用于不同的环境及条件。

# 七、补充:
# 1、分析一下 fuzz_out 输出的目录结构:
(1)由于之前尝试了并行模式所以在输出文件夹内,会单独生成不同的 M/S 的文件夹
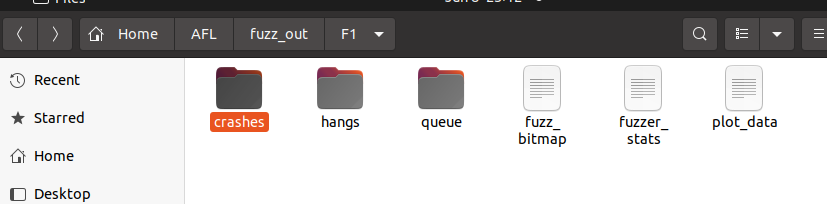
(2)输出文件的目录结构由 crashes、hangs、queue、bitmap、stats、plot_data 组成
-
crashes:主要是 fuzzing 过程中产生异常崩溃的 crash 文件。
-
hangs:记录当异常导致程序挂起(超时)的用例。
-
queue:记录了独特(不同)执行路径的测试用例。
-
fuzz_bitmap:程序被 fuzzing 的函数映射。
-
fuzzer_stats:记录了 fuzzer 的执行状态。
-
plot_data:用于 afl-plot 绘图。
# 最后
暂时搁置的内容:通过在网上找到的资料看到很多师傅对 afl 很多文件进行了更改,这需要对 afl 的源码进行细致的分析,目前不知道要深入做些什么,所以就没继续深究下去,其次,有的师傅在做实验的时候用到了 LAVA-M 数据集进行真实环境测试,目前不知道是否要研究这块内容,并且需要服务器环境,因此暂时搁置。再者,很多师傅都会研究 AFL 的头文件,我也看了很多相关的内容,内容涉及原理比较复杂,虽然可以看懂大概逻辑,及要表达的意思,但是感觉自己没能深入到点上,怕做无效的深入浪费时间,暂时搁置。